RNN的特點在於輸出除了被當下的input影響外,之前input的東西也會被記憶在hidden layer的參數內,利用此參數可以記憶之前Input的內容,再將其輸入到下一次Input中的同一個hidden layer參數。
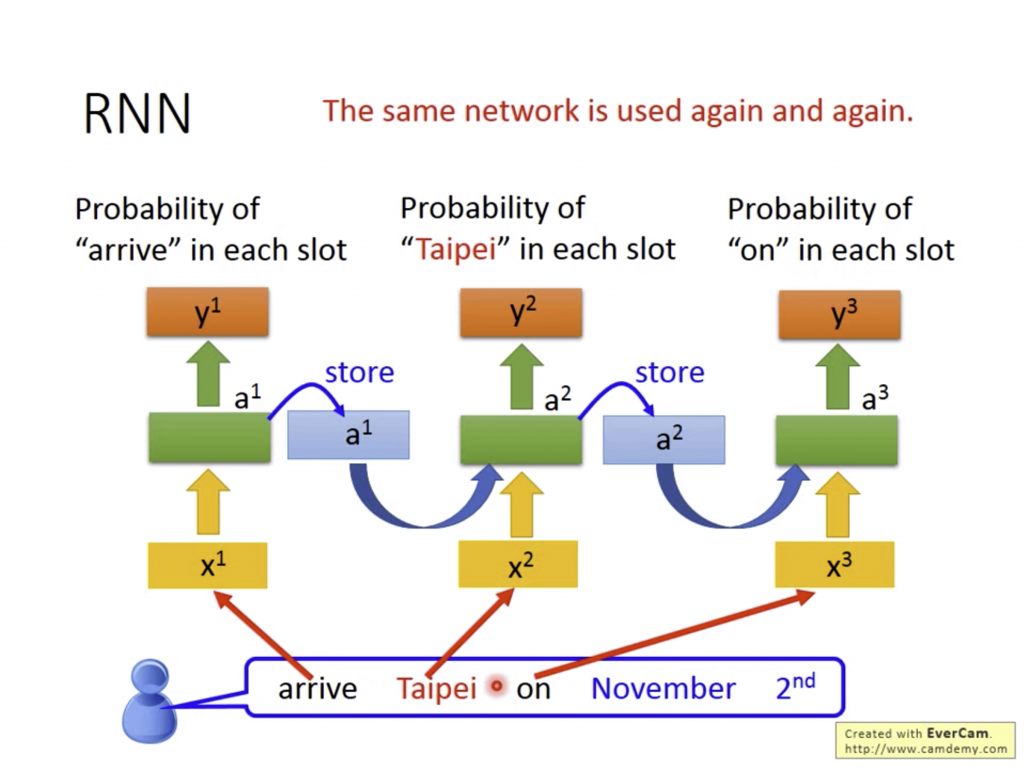
可以發現除了一個一個的資料本身以外,資料的先後順序也會影響到最後的Output。畢盡我們的文法本來就會照著先後順序說,我們在理解一個句子的時候也會看看上下文去理解句子的意思。
其實Recurrent Neurel Netowrk的基本概念僅此,如果看不懂也無仿,只要知道重點是RNN會多看資料的先後順序及關係影響最後的輸出就好了。
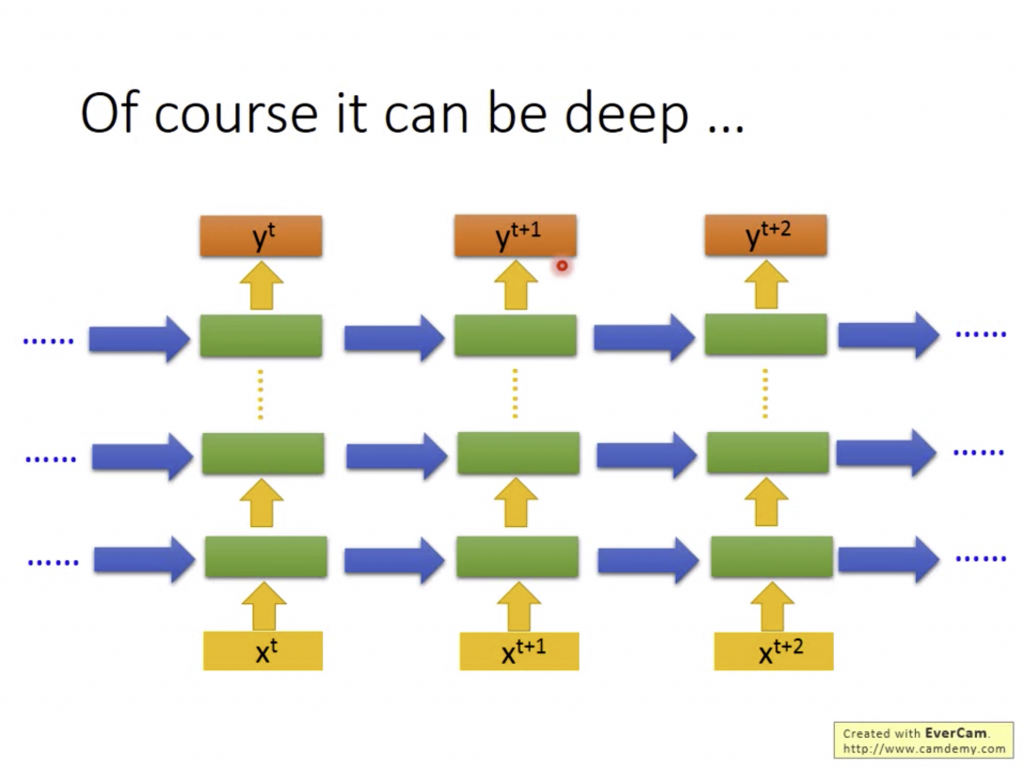
(這張投影片的意思是你可以堆很多很多層hidden layer,好多好爽好慢QQ)
Recurrent Neurel Netowrk的變形有Elman Network和Jorden Network:
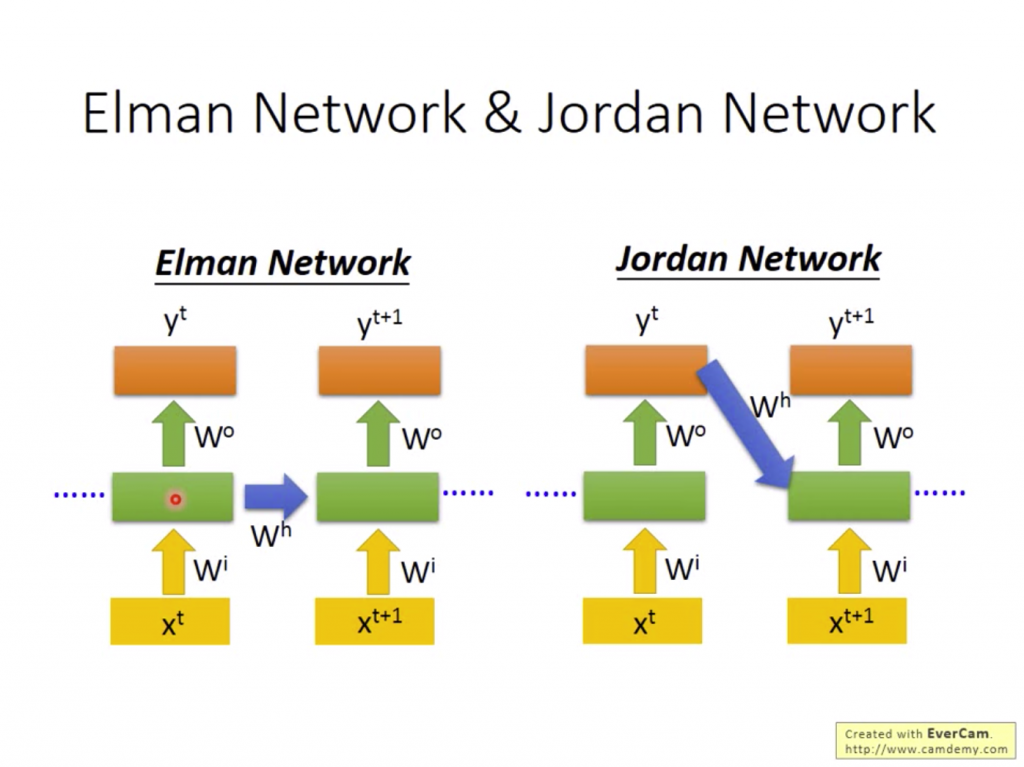
Jorden Network因為有Output的目標,所以Jorden Network的成效正常情況下會比Elman Network還要高。
我們在看一段文字的時候雖然接收的次序是從前到後,但有時候要聽到後面的意思才會了解前面的語意。將此概念套入RNN中的話,可以看成我們將整個Input都看過一遍的情況下,輸出每個單獨Input經不同參數的hidden layer的加總。
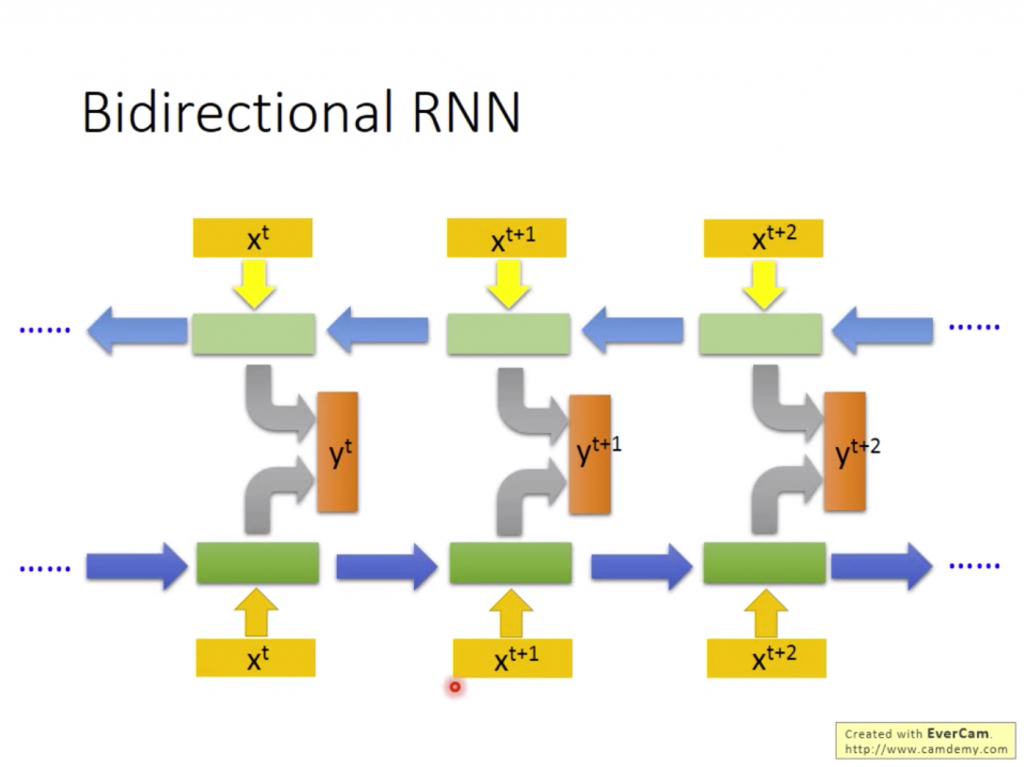
以上都是以最基本的RNN延伸出的模型,但其實看到這裡可能會覺得很奇怪,因為如果前面的資料已經跑過去很多時,Output的值可能會越來越大,或者是每個hidden layer能夠參考的記憶只有上一個資料。於是Long Short-term Memory可以將這些問題都解決。
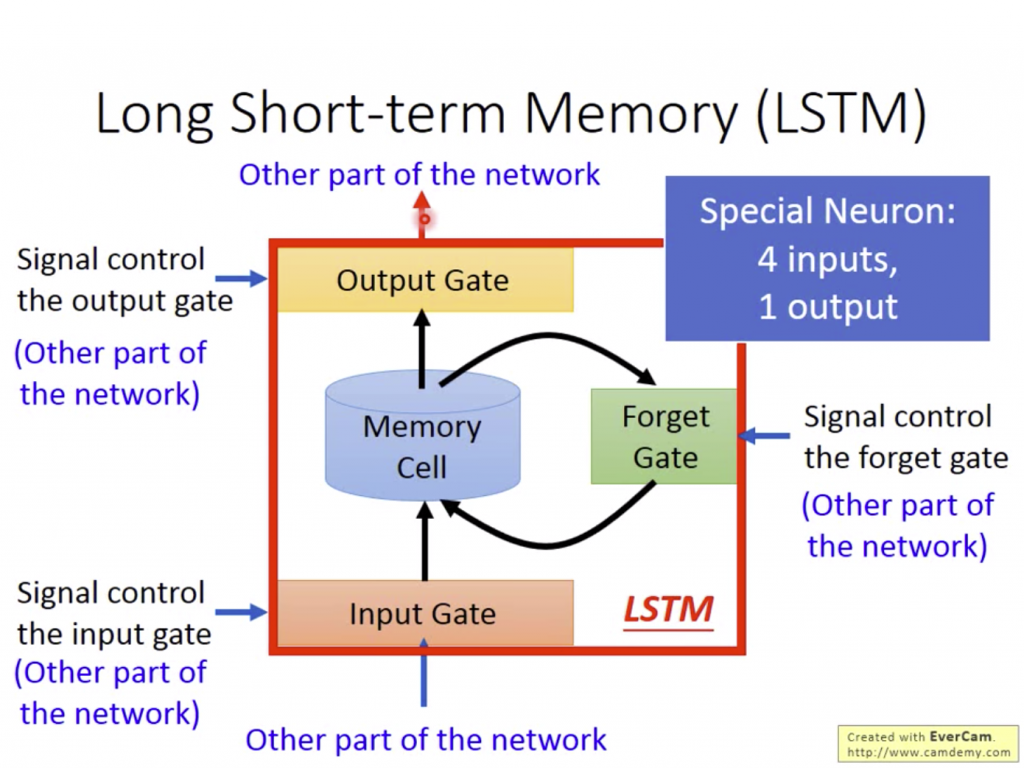
請把 dash 放在 Short 和 term 中,原本的Short-term Memory只能記住上一個資料,而LSTM只要不把Forget get關掉就可以讓資料一直傳遞下去。 - 李宏毅


 iThome鐵人賽
iThome鐵人賽